
Imagine a city where its operators are autonomously responding to live alerts, proactively handling emergencies, and utilizing visual AI agents to streamline efficiency. This goes beyond simple video processing; it’s about actively interpreting what happens across the entire public safety and security landscape in real time every moment of the day.
The Scale of Data and the Need for Intelligence
To enhance public safety and smart city applications, a centralized government entity needed to handle continuous live streams through intelligent video ingestion and agentic processing. With tens of thousands of cameras spread across the country, these initiatives quickly amass hundreds of petabytes of data that need to be stored in the systems and processed continuously.
The real challenge with understanding sensor-based data is turning it into actionable insights in near real-time, enabling fast and effective resolution for public safety scenarios, leveraging raw streams and maintaining a multimodal approach.
Typically, a city’s infrastructure was built around multiple separate video ingestion and analytics components. Each piece of hardware and software was specialized for distinct roles, including storage arrays, traditional databases, some basic computer vision capabilities, and middleware layers for event triggering. More importantly, it was not ready for running any large-scale AI vision workloads, nor agentic workflows.
From Object Detection to Agentic Intelligence
When coupled with large-scale inference workloads, which are designed to shift from standard object detection to real-time event interpretation and autonomous AI pipelines, you’re looking at a fragmented AI system of unprecedented complexity and capability.
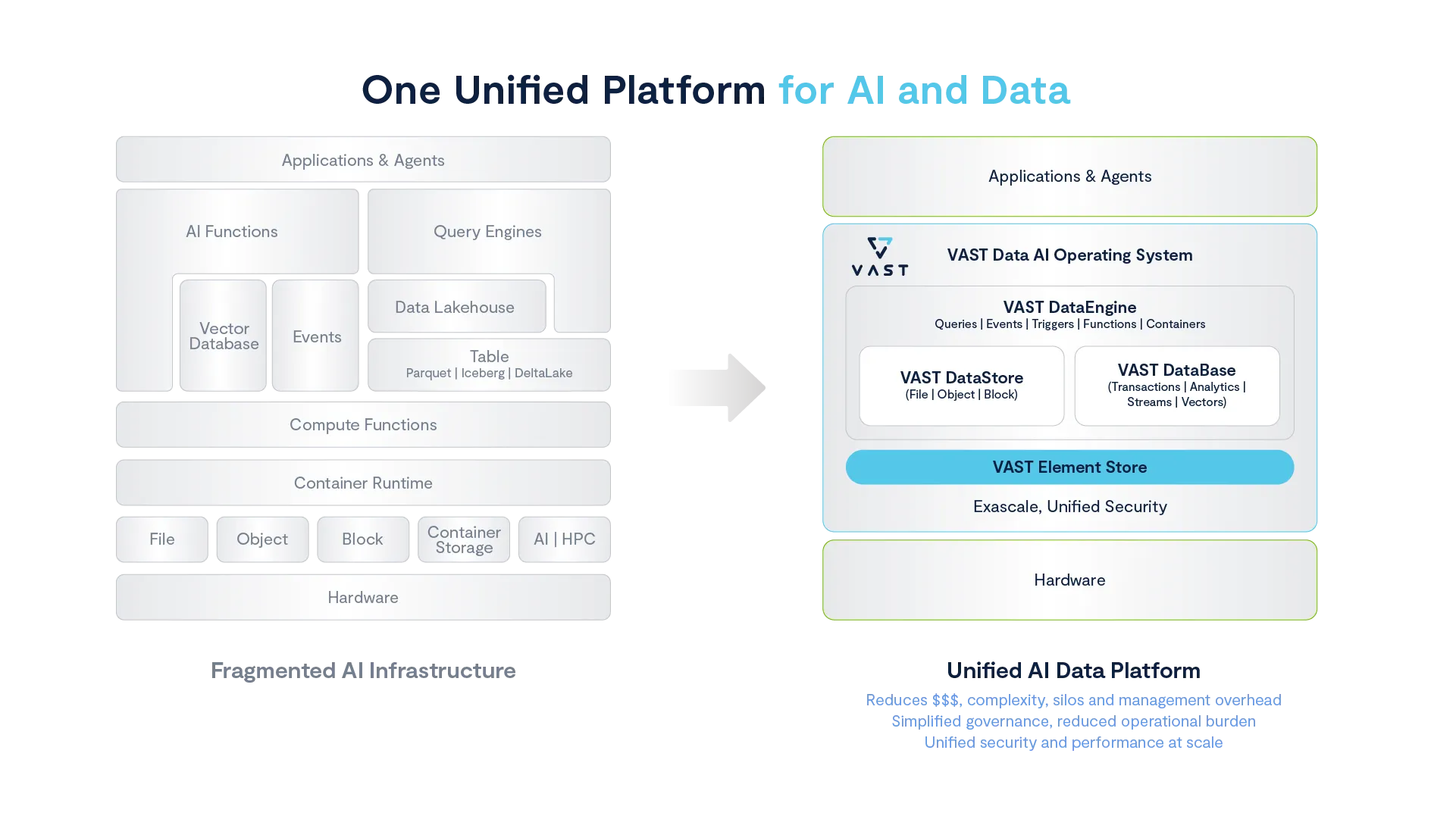
Fragmented infrastructure has become the norm, with databases, object stores, and vector engines operating in silos. This often means managing 10+ products that require auditing, tuning, integration, maintenance, governance, and scaling. Stitching them together creates ongoing bottlenecks, increases latency and drives up operational overhead.
Data duplication and inconsistent synchronization between components worsened latency problems and reduced system-wide reliability. Moreover, fragmented security policies made compliance and auditability extremely challenging, increasing organizational risk and slowing the adoption of advanced, autonomous analytics.
To complicate matters, the city’s vision was ambitious. It did not just want to observe, it aimed to accelerate intervention times, often without human input, using sophisticated, autonomous AI agents.
These agents would not simply trigger alarms based on predefined rules. Instead, they would understand context, identify complex patterns, reason deeply about unfolding situations, and then initiate responses independently. As one might imagine, this ambition added another layer of complexity. Such advanced reasoning demands immediate access to both current and historical data, processed by the most advanced GPU-embedded systems available, all running in seamless harmony.
The Architecture for Unifying Data, Compute and Intelligence at Scale
The government entity turned to the VAST AI OS to help modernize existing infrastructure and add agentic capabilities. Rather than stitching together separate storage, databases, vectors, and agentic services, the VAST AI OS integrates these elements tightly into one cohesive architecture.
The deployment includes the VAST DataStore, a high-performance multi-protocol layer handling file, object, and block data simultaneously. Above that layer sat the VAST DataBase, an integrated analytical and transactional structured data warehouse optimized specifically for real-time analytics and semantic vector storage and retrieval.
Semantic embedding, the process of transforming raw video into searchable vectors representing meaning, played a critical role. By embedding frames and associated metadata within a semantic vector space, the system could instantly retrieve relevant context from past data whenever needed.
This capability was pivotal, allowing the AI agents to quickly access historical patterns and respond both rapidly and accurately.
To perform sophisticated inference at scale, the government entity made a significant investment in NVIDIA GPUs to be distributed across both on-prem and a sovereign cloud environment, interconnected by direct networking fabrics.
A Smart City Use Case applying VAST AI OS
To enable a next-gen shift into automating operations across cities, VAST is working with a major city to first acquire the government made a significant investment in NVIDIA GPUs to be distributed across both on-prem and a sovereign cloud environment, interconnected by direct networking fabrics. Data flowed without interruption, with GPUs accessing storage directly through GPU-direct storage and Remote Direct Memory Access (RDMA), ensuring the lowest possible latency. No matter how complex or intensive the task, data bottlenecks were effectively eliminated.
The focus on deep integration did not stop at hardware. To orchestrate real-time interactions between data ingestion, inference, and automated action, VAST built the DataEngine. This core software layer handled queries, events, and triggers with exceptional speed and reliability, effectively becoming the nerve center for the entire city-scale analytics system.
As part of the proposed ingest solution, deploying video analytics agents was an integral part of improving efficiency and adding agentic reasoning. Together with NVIDIA AI Blueprint for Video Search and Summarization (VSS), integrated with VAST AI OS, we are able to deliver a scalable, low-latency, and accurate AI video infrastructure. The goal is to support high-volume video streams with autonomous ingestion while leveraging existing components from the current video pipeline developed by a local System Integrator partner.
The GPU-accelerated ingestion pipeline includes key VSS components such as the Stream Handler (which segments video streams into chunks), NVDEC decoder (which converts chunks into raw frames), and Intelligent Frame Selection. These work in tandem with Computer Vision (CV) and Vision Language Models (VLMs). Relevant clips are then sent to the VLM for video understanding and summarization. We used an 8B parameter VLM since it was suitable for this specific task and balance of performance and efficiency. Additional key components include NVIDIA NeMo Retriever embedding and reranking models for fast, accurate responses and the NVIDIA Riva leaderboard-topping automatic speech recognition model.
Autonomous Agents In Action
With these unified elements in place, the true innovation emerged in the agentic AI workflow itself.
The agents operated autonomously, sophisticated workflows, with some conducting multi-step retrieval and reasoning. Suppose, for instance, a disturbance appeared somewhere in the city, like a suspicious gathering or an escalating argument at a transit hub. Cameras capturing this scene would stream their data into the ingestion agents, instantly decoding and extracting relevant frames for summarization. Parallel inference agents investigate the unfolding situation in real-time, leveraging the full computational power of the GPU infrastructure.
These inference agents swiftly recognized the anomaly and triggered a suite of action agents equipped with access to systems and APIs. These agents further determine the correctness of their anticipated actions, align with predefined policy-driven actions, and add a human-in-the-loop for another pair of eyes.
All decisions were logged in comprehensive semantic records, allowing instant post-event auditing, continuous improvement, and refinement of future AI-driven responses.
Infrastructure that Matches Intelligence
The network infrastructure supporting this workflow was itself remarkable, using Cisco ACI fabric, NVIDIA Spectrum Ethernet switches, and high-speed optical connections. Dedicated GPU clusters interconnected via InfiniBand and high-throughput Ethernet eliminated latency bottlenecks, ensuring real-time data processing remained consistently smooth and uninterrupted. This deployment is among the first to leverage VAST AI OS, a new class of GPU-accelerated enterprise storage systems designed for AI workloads.
Yet, beyond its impressive technological achievements, the real story of this project lies in its profound applicability beyond a single city’s public safety scenario, and the value of saving lives.
The unified architecture, semantic embedding capabilities, agentic automation with VSS, and real-time inference pipeline are universally relevant.
Similar architectures can revolutionize industrial manufacturing, providing instantaneous predictive maintenance; financial services, enabling real-time risk analysis; healthcare, improving patient monitoring and diagnostics; or media, enhancing content discovery and personalization.
VAST set a new, first of its kind AI architecture for large-scale agentic video inference.
The integration of previously fragmented layers, the seamless orchestration of sophisticated AI reasoning, and the scale at which it operated collectively demonstrated what modern data architectures could achieve when pushed to their absolute limits.
The Visionary Roadmap for AI at Scale
This narrative is not just about impressive technical accomplishments. It represents a shift in how organizations will approach real-time data intelligence at unprecedented scale. The successful deployment of this unified infrastructure serves as a compelling proof-point, illustrating a future in which intelligent systems do not merely support human decision-making but independently improve and accelerate it.
As the scale and complexity of data continue to grow exponentially, VAST’s infrastructure provides a visionary roadmap, showcasing precisely what is possible when intelligence, scale, and speed converge within a single, unified platform.
Have ideas on where large-scale agentic AI could go next? Continue the discussion with peers and VAST experts on Cosmos.


